Remember that our goal is to estimate the linear relationship between data observations of response variable, \(y\), and its measured covariate, \(x\), following: \(Y = XB + \epsilon\), where \(\epsilon \sim N(0, \sigma^2 I).\) Our coefficients to estimate are therefore \(\hat{B}\), which is a column vector of the intercept and slope. We also estimate the standard deviation of the residuals (i.e., residual error), \(\hat{\sigma}\). To estimate the coefficients, we are attempting to minimize the residual sum of squares, \(|| \epsilon || ^ 2\). See Footnotes 4.12.1 for more information regarding this notation.
4.2 Generate the data
We’ll start with a very small data set to emphasize the basics, and then the in-class activity will go into more depth. Here, we’ll implement the OLS estimation with a single covariate that we demonstrated in lecture.
n=4# number observationsp=2# number of parameters# Covariate:x0=c(1,1,1,1)# placeholder for interceptx1=c(2,3,5,1)# value of xxmat=matrix(data =c(x0,x1), nrow =n, ncol =p)xmat
# residualsepsilon=c(0, -1, 1, 3)# Data observations:y=xmat%*%betas+epsilon
4.3 Plot the relationship
# Plot in layers## Create a blank plotting canvas, specifying axis limitsplot(x=NA,y=NA, xlab ="x", ylab ="y", ylim =c(0,max(y)), xlim =c(0,max(x1)))## Add data pointspoints(y~x1, pch =19, cex =2)## Add known linear relationshipabline(coef =betas, col ="black", lwd =2)# Show the residuals:segments(x0 =x1, x1 =x1, y0 =y, y1 =y-epsilon)# Show the model predictions, \hat{y}:y_hat=xmat%*%betaspoints(y_hat~x1, cex =1.25)
4.4 Estimate the coefficients using R’s lm() function
# Run the model:lm_out=lm(y~1+x1)# Show the summary outputsummary(lm_out)
Call:
lm(formula = y ~ 1 + x1)
Residuals:
1 2 3 4
-1.029 -1.657 1.086 1.600
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.7714 2.0500 2.815 0.106
x1 1.6286 0.6565 2.481 0.131
Residual standard error: 1.942 on 2 degrees of freedom
Multiple R-squared: 0.7547, Adjusted R-squared: 0.6321
F-statistic: 6.153 on 1 and 2 DF, p-value: 0.1313
# Extract the estimated coefficientslm_coef=coef(lm_out)lm_coef
(Intercept) x1
5.771429 1.628571
4.5 Estimate the coefficients manually
Now we will use the matrix algebra and derivation of normal equations to estimate the intercept and slope from the observations, \(Y\). Remember that we estimate the coefficient vector, \(\hat{B}\) from: \[X^TX \hat{B} = X^T Y\]\[\hat{B} = (X^TX)^{-1} X^T Y\] These equations include the multiplicative inverse matrix, \((X^TX)^{-1}\). See the Footnotes 4.12.2 for more information about inverse matrices and the solve() function.
# Let's break up the normal equations into intermediates:xtx=t(xmat)%*%xmat## Use solve() to find inverse of xtx## why solve()? See Appendix, linked above.inv_xtx=solve(xtx)xty=t(xmat)%*%ybhat=inv_xtx%*%xty# More efficient:# Remember, xtx * bhat = xty# So we can use solve() againbhat_solve=solve(xtx, xty)# Are they the same?# How does this manual solution compare to lm()'s solution?
4.6 Plot the estimated relationships
# Plot in layers## Create a blank plotting canvas, specifying axis limitsplot(NA,NA, xlab ="x", ylab ="y", ylim =c(0,max(y)), xlim =c(0,max(x1)))## Add data pointspoints(y~x1, pch =19, cex =2)## Add known linear relationshipabline(coef =betas, col ="black", lwd =2)# Show the residuals:segments( x0 =x1, x1 =x1, y0 =y, y1 =y-epsilon,)# Show the model predictions, \hat{y}:y_hat=xmat%*%betaspoints(y_hat~x1, cex =1.25)# Add the lm() estimate:abline(coef =lm_coef, col ="orange", lty =2, lwd =2)# Add the manual OLS estimate:abline(coef =bhat_solve, col ="purple", lty =3, lwd =2)
4.7 Why are the \(\hat{B}\) different from true \(B\)?
Remember, we are estimating the coefficients by minimizing the sum of squared errors (SSE), \(|| \epsilon ||^2\).
You can see that the OLS strategy minimized SSE, but this is actually lower than the true SSE.
4.8 Understanding Uncertainty in \(\hat{B}\)
While the OLS analysis estimates the regression coefficients, \(\hat{B}\), from the observed data \(Y\), our estimates of these coefficients have error (i.e., uncertainty), such that the estimates are only as good as the data. Specifically, if we have fewer data points (i.e., \(n\) is low), we have less certainty in \(\hat{B}\). In lecture, we showed, that: \[\hat{B} \sim N \left( B, (X^TX)^{-1} \hat{\sigma}^2 \right), \] and we know that \(\hat{\sigma}^2\) depends on sample size \(n\), following: \[\hat{\sigma}^2 \quad = \quad \frac{1}{n-p} (Y_{obs} - Y_{pred})^T (Y_{obs} - Y_{pred}) \quad = \quad \frac{1}{n-p} \hat{\epsilon}^T \hat{\epsilon}\]
Using these equations, we showed then that \(SE(\beta_i) = \sqrt{diag\left( (X^TX)^{-1} \right)_i \hat{\sigma}^2}\). Let’s calculate this manually and compare to the output of the lm() function.
# Extract the model summary, which has useful componentslm_out_summary=summary(lm_out)# Extract the estimated residual standard deviation, sigmaest_sigma=lm_out_summary$sigmaest_sigma
[1] 1.942017
# We already calculated (X^T X)^{-1} as inv_xtxbeta_cov_mat=inv_xtx*est_sigma^2beta_cov_mat
Compare these values to the output of the summary() of Section 4.4 in the column labelled Std. Error.
4.9 Confidence Intervals for \(\hat{B}\)
To calculate confidence intervals for \(\hat{B}\), we first must understand the \(t\) (a.k.a. Student’s \(t\)) probability distribution. This distribution represents the case when we are estimating the mean of a normally distributed variable and either the sample size is small or the variable’s standard deviation is unknown. Essentially, the \(t\) distribution increases the uncertainty (i.e., variance) in cases of low sample size (i.e., small \(n\)). With low sample size (and/or high number of parameters), the degrees of freedom of the \(t\)-distribution, \(\nu\) is low, whereas with high sample size, \(\nu\) is large. As \(\nu\) approaches infinity, the \(t\)-distribution approximates the standard normal distribution (i.e., \(N(\mu, \sigma)|\mu=0,\sigma=1\)).
It is the case for \(\hat{B} \sim N \left( B, (X^TX)^{-1} \hat{\sigma}^2 \right)\) that we do not know the mean (\(B\)), and we are estimating the variance, \(\hat{\sigma}^2\). Specifically, we are estimating the true mean vector, \(B\), as \(\hat{B}\), and we are estimating the variance of the residuals as \(\hat{\sigma}^2\). We can therefore re-write the uncertainty in \(\hat{B}\) as a multivariate \(t\) distribution: \[(\hat{B} - B) \sim t_{\nu} \left( 0, \Sigma \right),\] where the means are zero, \(\nu\) is the degrees of freedom (i.e., \(n-p\)), and \(\Sigma = (X^TX)^{-1} \hat{\sigma}^2\). \((\hat{B} - B)\) represents the deviation of the estimated coefficients from the true coefficients, which is why the distribution is centered around zero. It is perhaps easier to separate the individual estimated coefficients, \(\beta_i\), into their separate \(t\)-distributions: \[\frac{(\hat{\beta}_i - \beta_i)}{SE(\hat{\beta}_i)} \sim t_{\nu}\]\[(\hat{\beta}_i - \beta_i) \sim t_{\nu} SE(\hat{\beta}_i),\] which shows that the \(t\)-distribution that describes the deviation of regression coefficients from the true value of those coefficients is scaled by the uncertainty in the estimated coefficients \(SE(\hat{\beta}_i)\). As shown in Dr. Barber’s materials, using this information, we can derive the confidence interval (at the \(\alpha\) confidence level) calculation for \(\hat{\beta}_i\) as: \[ \hat{\beta}_i \pm t \left(\frac{1-\alpha}{2}, \nu \right) SE(\hat{\beta}_i),\] where the \(t()\) notation represents the critical value of the \(t\)-distribution, \(t_{crit}\), with \(\nu\) degrees of freedom, for which \(P(z \le t_{crit}) = \frac{1-\alpha}{2}\), and \(z\) is a continuous, random variable. This critical value can be calculated in R using the qt() function, which we show below.
Covariance of \(\hat{\beta}_i\)
Although it is convenient and easier to digest the confidence interval of individual \(\hat{\beta}_i\), we must realize that the estimates of the \(\beta_i\) can covary (i.e., have non-zero covariance), which is quantified in the variance-covariance matrix of \(\hat{B}\), \((X^TX)^{-1} \hat{\sigma}^2\). We will show why this is important below.
Let’s manually calculate the 95% confidence intervals in \(\hat{B}\) and compare to R’s internal function confint().
# Extract the degrees of freedom from the model (\nu)# which can also be calculated as n - pt_df=lm_out$df.residual# Calculate t critical for alpha = 0.05# This will give us the 95% conf interval (CI)t_crit=qt(1-(0.05/2), df =t_df)# Calculate the upper and lower CI for both betasci_int=lm_coef[1]+c(-1,1)*t_crit*se_beta[1]ci_slope=lm_coef[2]+c(-1,1)*t_crit*se_beta[2]# Construct a table of valuesci_mat=rbind(c(lm_coef[1], ci_int),c(lm_coef[2], ci_slope))colnames(ci_mat)=c("coef", "lowCI", "highCI")rownames(ci_mat)=c("intercept", "slope")ci_mat
# Compare these manual calculations to built-in# function confint(), which by default extracts the # 95% CI for a lm() model's coefficientsconfint(lm_out)
4.10 Propagate uncertainty in \(\hat{B}\) for predictions of \(Y\)
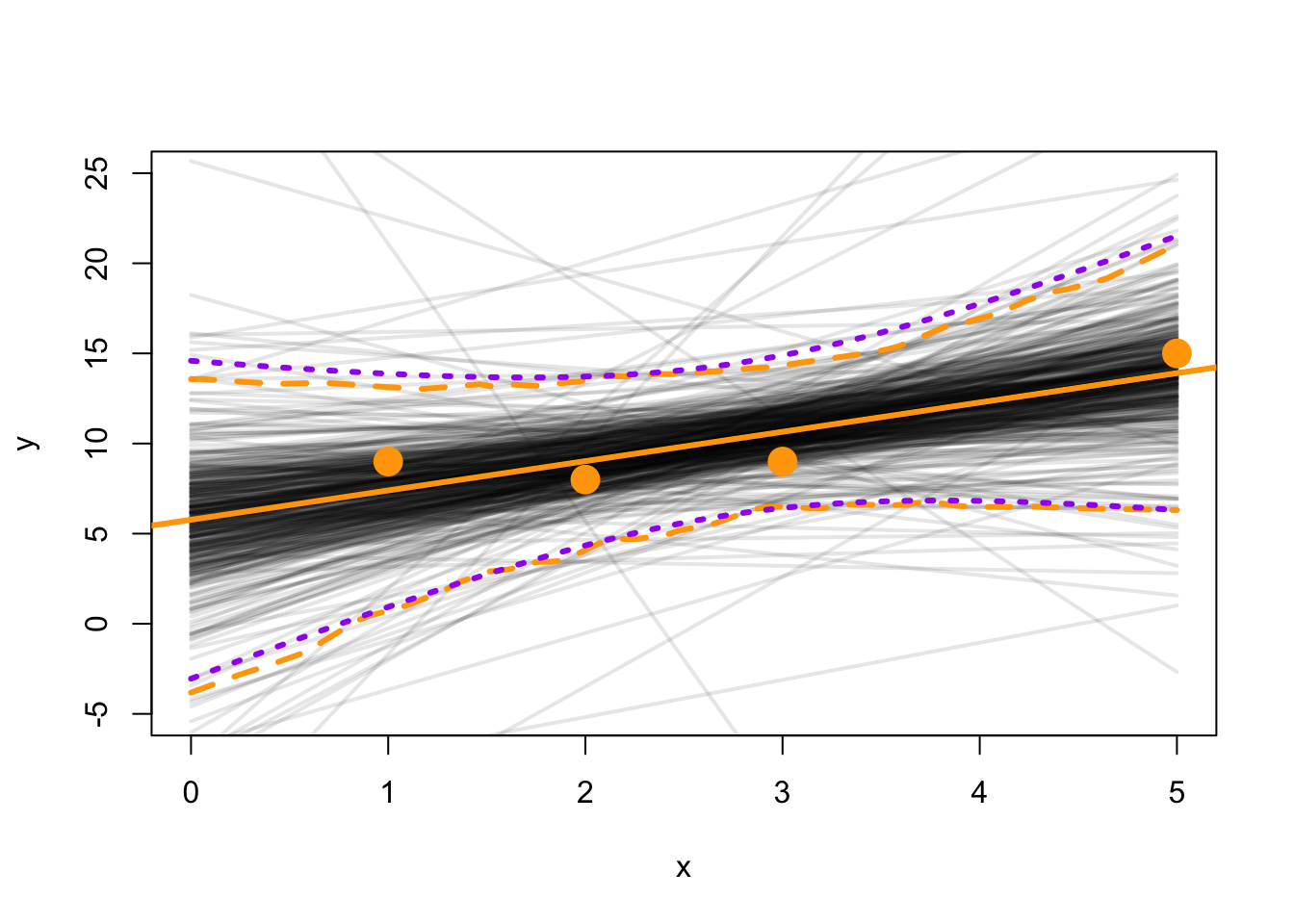
There are several ways to calculate and visualize our uncertainty in model predictions of observed data \(Y\) and unobserved data of the dependent variable (i.e., interpolation). The colored lines drawn on the figure in Section 4.6 represent the expected values of \(Y\) based on the OLS analysis’ estimate of \(\hat{B}\), but this line does not include uncertainty in these coefficient values.
4.10.1 Multivariate \(t\)-distribution method
First, we will calculate uncertainty by sampling from the multivariate \(t\) distribution that represents error in regression coefficients, \(\hat{B}\).
# We will "bootstrap" 1000 samples of intercept and slopeset.seed(3)n_samp=500# Draw from the multivariate t # which represents (\hat{B} - B)test_mat_deviates=mnormt::rmt(n_samp, mean =c(0,0), S =beta_cov_mat, df =t_df)# Now calculate the realized intercept and slope# using the t-distributed deviatestest_mat_t=cbind(lm_coef[1]+c(test_mat_deviates[,1]),lm_coef[2]+c(test_mat_deviates[,2]))# Calculate the 95% quantiles and compare to the # calculated 95% confidence intervals from aboveapply(test_mat_t, MARGIN =2, # applies function (FUN) to columns (dim 2) FUN =quantile, probs =c(0.025, 0.5, 0.975))
# Plot the relationship between intercept and slope# Notice the covarianceplot(test_mat_t, xlab ="Intercept", ylab ="Slope")
Next, for each pair of intercept and slope randomly drawn above, we will calculate the expected values of \(Y\) across the range of covariate \(x\). We will then summarize the 95% quantile of expected \(Y\) at each value of \(x\) in this interpolation. To do this, we need a function to calculate the expected value of \(Y\). This function will have the intercept and slope as inputs and will output the expected values of \(Y\) across a range of \(x\). Then, we will apply() this function using all of the values of intercept and slope, in a vectorized and therefore very efficient manner, rather than using any for loops.
# Create a matrix that holds the values of x# over which we want to interpolate the expected# values of Yx_fake_mat=cbind(rep(1, times =100),seq(0,max(x1),length.out =100))# Create a function that will calculate the expected valuesy_hat_fun=function(x, x_mat){x_mat%*%x}# Apply this function to all intercepts and slopes that# we drew from the multivariate ty_pred_mt=apply(test_mat_t, 1, y_hat_fun, x_mat=x_fake_mat)# Summarize the 95% quantile of the expected value of Y# at each value of x y_pred_mt_summary=apply(y_pred_mt, 1, quantile, probs =c(0.025, 0.975))str(y_pred_mt_summary)
R has a built-in function predict() (see specific variant predict.lm()) which calculates expected values of the dependent variable from a linear regression model estimated using the function lm().
# Note that 'newdata' must be a data frame that includes the ranges# of each covariate in the regression model for which you want # to generate interpolated or predicted values of the dependent variable# Here we are calculated the expected values as well as the # 95% confidence intervals for those expected valuesy_predict=predict(lm_out, newdata =data.frame(x1 =c(x_fake_mat[,2])), interval ="confidence", level =0.95)str(y_predict)
Let’s visualize the output of the two methods to compare.
# plotplot(x=NA,y=NA,xlab ="x", ylab ="y", xlim =c(0,max(x1)), ylim =c(-5, 25), pch =19)# Plot the expected values of Y for each pair of int/slope for(iin1:n_samp){lines(y_pred_mt[,i]~x_fake_mat[,2],# Reduce the opacity of each line col =scales::alpha("black", alpha =0.1), lwd =2)}# Add the data pointspoints(y~x1, col ='orange', pch =19, cex =2)# Add the expected values of Y from \hat{B}abline(coef =lm_coef, col ="orange", lwd =3)# Add the conf int of expected Y using multivariate tlines(y_pred_mt_summary[1,]~x_fake_mat[,2], lty =2, lwd =3, col ="orange")lines(y_pred_mt_summary[2,]~x_fake_mat[,2], lty =2, lwd =3, col ="orange")# Add the conf int of expected Y using predict() functionlines(y_predict[,"lwr"]~x_fake_mat[,2], lty =3, lwd =3, col ="purple")lines(y_predict[,"upr"]~x_fake_mat[,2], lty =3, lwd =3, col ="purple")
There is yet a third option to calculate the uncertainty in predicted (i.e., interpolated or extrapolated) values of \(Y\), which is to derive an exact calculation of the confidence interval using the \(t\) distribution, similar to that shown in Section 4.9. See Ch4.1 of Dr. Barber’s book for this derivation.
4.11 Multiple Linear Regression
So far, we have only discussed a single input variable in our model, which is a simple linear regression. When we have multiple input variables, we are dealing with multiple linear regression analysis, so the model looks like: \[y_i = \beta_0 + \beta_1 x_{1,i} + \beta_2 x_{2,i} + \dots + \beta_{p-1} x_{p-1,i} + \epsilon_i\] where \(p\) is the number of model coefficients and \(p-1\) is the number of input variables. Still, in matrix notation the model is \(Y = XB + \epsilon\), so the least squares regression analysis approach still works. However, our interpretation of the model coefficients becomes a bit more challenging.
Let’s look at a data set within the faraway package.
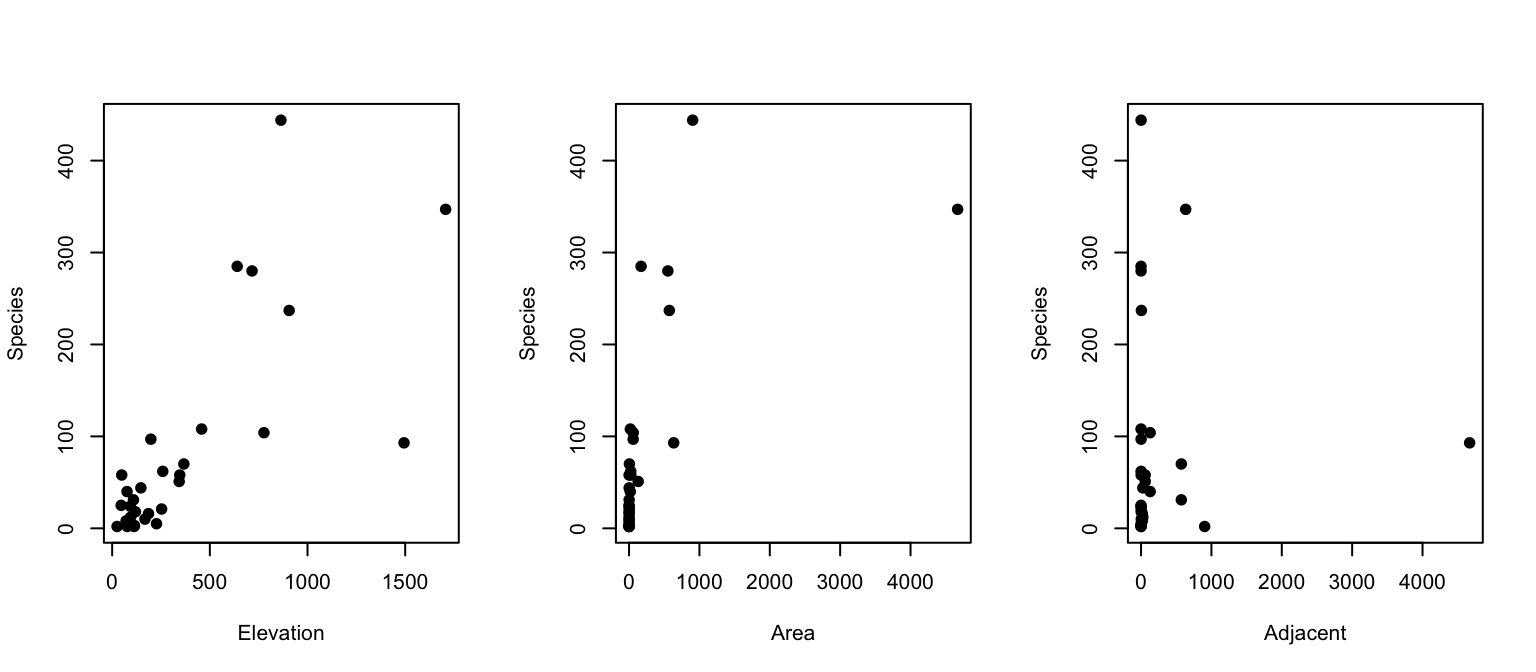
library(faraway)data(gala)# Plot the raw data relationshipspar(mfrow=c(1,3))plot(gala$Species~gala$Elevation, xlab ="Elevation", ylab ="Species", pch =19)plot(gala$Species~gala$Area, xlab ="Area", ylab ="Species", pch =19)plot(gala$Species~gala$Adjacent, xlab ="Adjacent", ylab ="Species", pch =19)
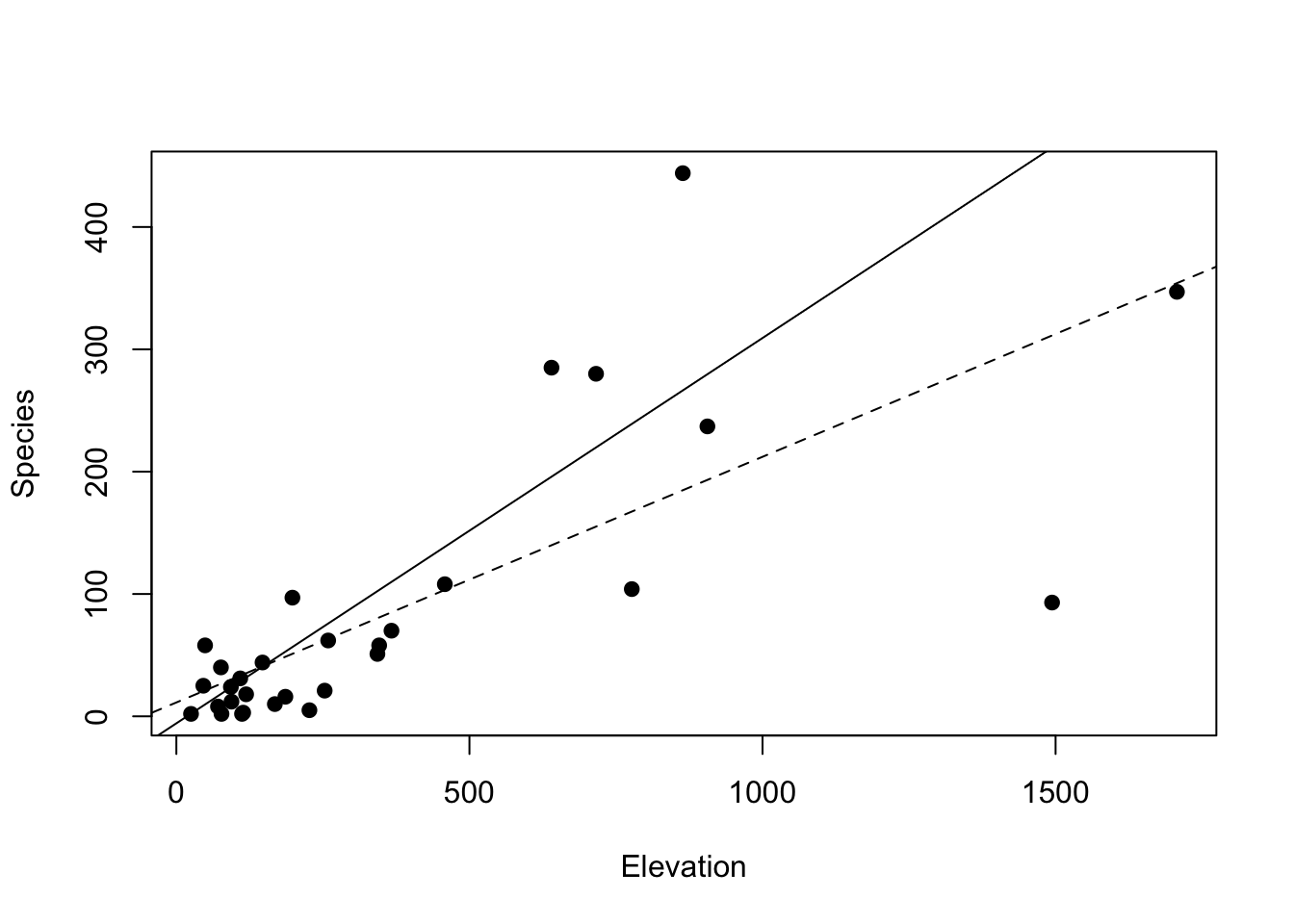
par(mfrow=c(1,1))# Conduct multiple and single linear regressionm, focusing on Elevationm1=lm(Species~Elevation+Area+Adjacent, data =gala)m2=lm(Species~Elevation, data =gala)coef(m1); coef(m2)
(Intercept) Elevation Area Adjacent
-5.71892681 0.31498110 -0.02031217 -0.07527974
What we see above is how the addition of Area and Adjacent input variables into the model “adjusts” the effect of Elevation, leading to two unique estimates of the slope (i.e., effect) of Elevation. Let’s probe multiple linear regression more closely by using simulated data.
First, let’s simulate a model with 80 data points that correspond to observations of 4 input variables and one outcome variable. Note that in Footnotes 4.12.3, we show a case with a categorical/binary input variable.
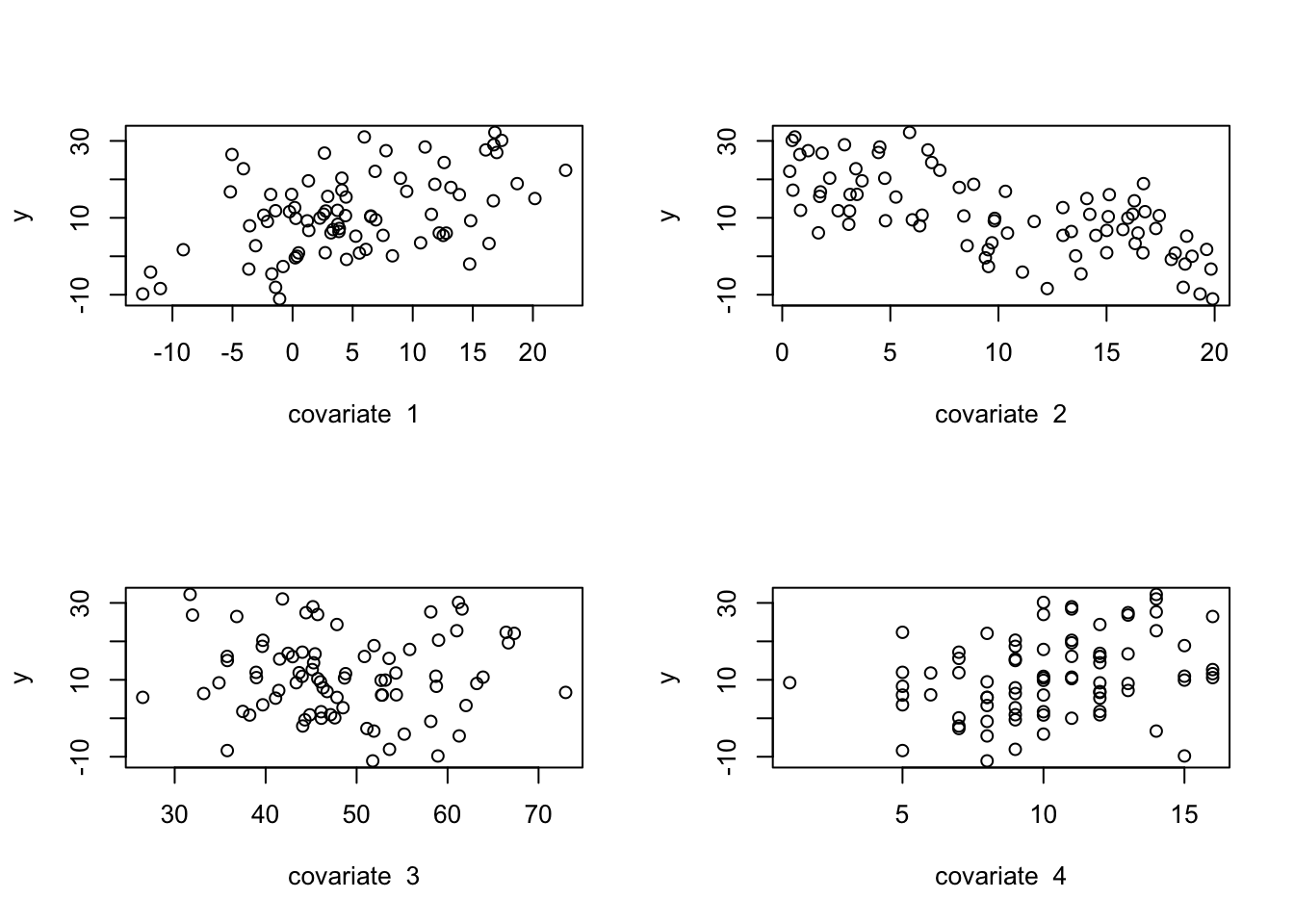
n=80n_covariate=4p=n_covariate+1betas=vector("numeric", length =p)xmat=matrix(0, nrow =n, ncol =p)sigma=2.25# Column for interceptxmat[,1]=1# Generate the covariate data randomly:set.seed(5)xmat[,2]=rnorm(n, mean =5, sd =8)xmat[,3]=runif(n, min =0, max =20)xmat[,4]=rchisq(n, df =50)xmat[,5]=rpois(n, lambda =10)par(mfrow=c(2,2))for(iin2:p){hist(xmat[,i], main =paste("covariate ", i-1))}
# Set the betas:betas[1]=1.0betas[2]=0.75betas[3]=-1.2betas[4]=0.0betas[5]=1.8# Calculate the observed 'y', adding residual errory=xmat%*%betas+rnorm(n, mean =0, sd =sigma)par(mfrow=c(1,1))hist(y)
How do we figure out the expected value of \(y\) for a particular situation? Here’s an example. What is the expected value of \(y\) when \(x_2 = 0.5\), but the rest of the input variables are at their average values?
# Written out long-ways:pred_y=betas[1]*1+betas[2]*mean(xmat[,2])+betas[3]*0.5+betas[4]*mean(xmat[,4])+betas[5]*mean(xmat[,5])pred_y
[1] 22.6006
Now let’s use ordinary least squares regression to estimate our model coefficients from the data, and then compare these to our “known” values of the model parameters.
# Run the model:m1=lm(y~0+xmat)# Note that the following two models give the same results#m2 = lm(y ~ 0 + X1 + X2 + X3 + X4 + X5, data = data.frame(xmat))#m3 = lm(y ~ 1 + X2 + X3 + X4 + X5, data = data.frame(xmat))summary(m1)
Call:
lm(formula = y ~ 0 + xmat)
Residuals:
Min 1Q Median 3Q Max
-6.4388 -1.4712 0.2816 1.5305 5.0032
Coefficients:
Estimate Std. Error t value Pr(>|t|)
xmat1 1.589838 1.759860 0.903 0.369
xmat2 0.737086 0.035629 20.688 <2e-16 ***
xmat3 -1.295274 0.044252 -29.270 <2e-16 ***
xmat4 -0.003676 0.028481 -0.129 0.898
xmat5 1.826125 0.088971 20.525 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.388 on 75 degrees of freedom
Multiple R-squared: 0.9763, Adjusted R-squared: 0.9747
F-statistic: 616.7 on 5 and 75 DF, p-value: < 2.2e-16
#summary(m2)#summary(m3)# Compare known `betas` to estimated coefficientscbind(betas, coef(m1))
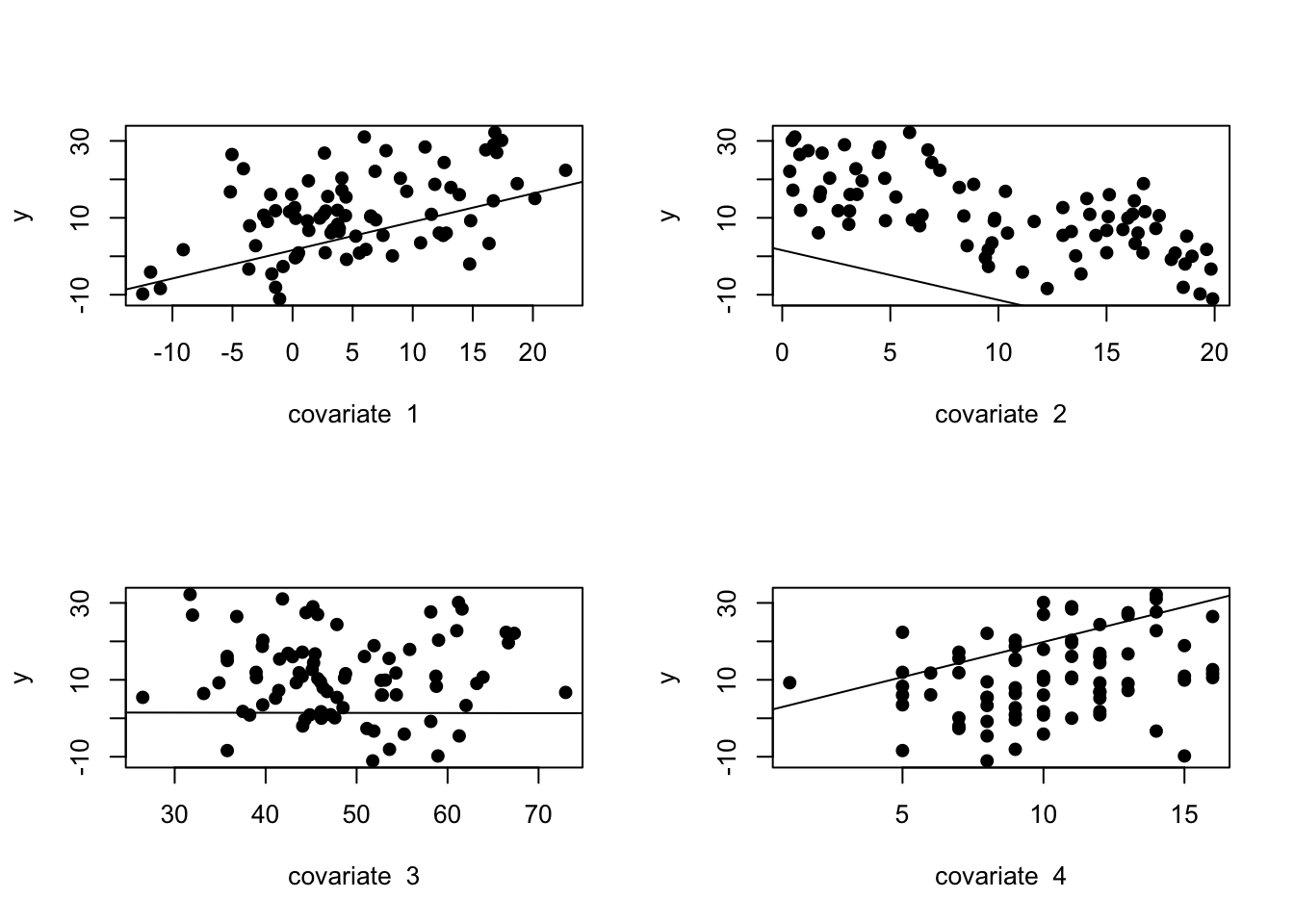
# plot the regression lines with ablinecoef_m1=coef(m1)par(mfrow=c(2,2))for(iin2:p){plot(y~xmat[,i], pch=19, xlab =paste("covariate ", i-1), ylab ="y", ylim =range(y))abline(coef=coef_m1[c(1,i)])}
Well, those regression lines do not look correct. That is because we are interpretting the slopes and intercepts a little incorrectly and not plotting them in the correct manner.
How to plot the output of lm() for multiple linear regression
When we isolate and visualize the relationship between the outcome and a single input variable, what we are really observing is the adjusted relationship, after accounting for the other input variables in the model. To understand the expected value of \(y\) for any particular value of the single input variable, we really need to set the other input variables to their mean value. Let’s demonstrate this below with the predict() function.
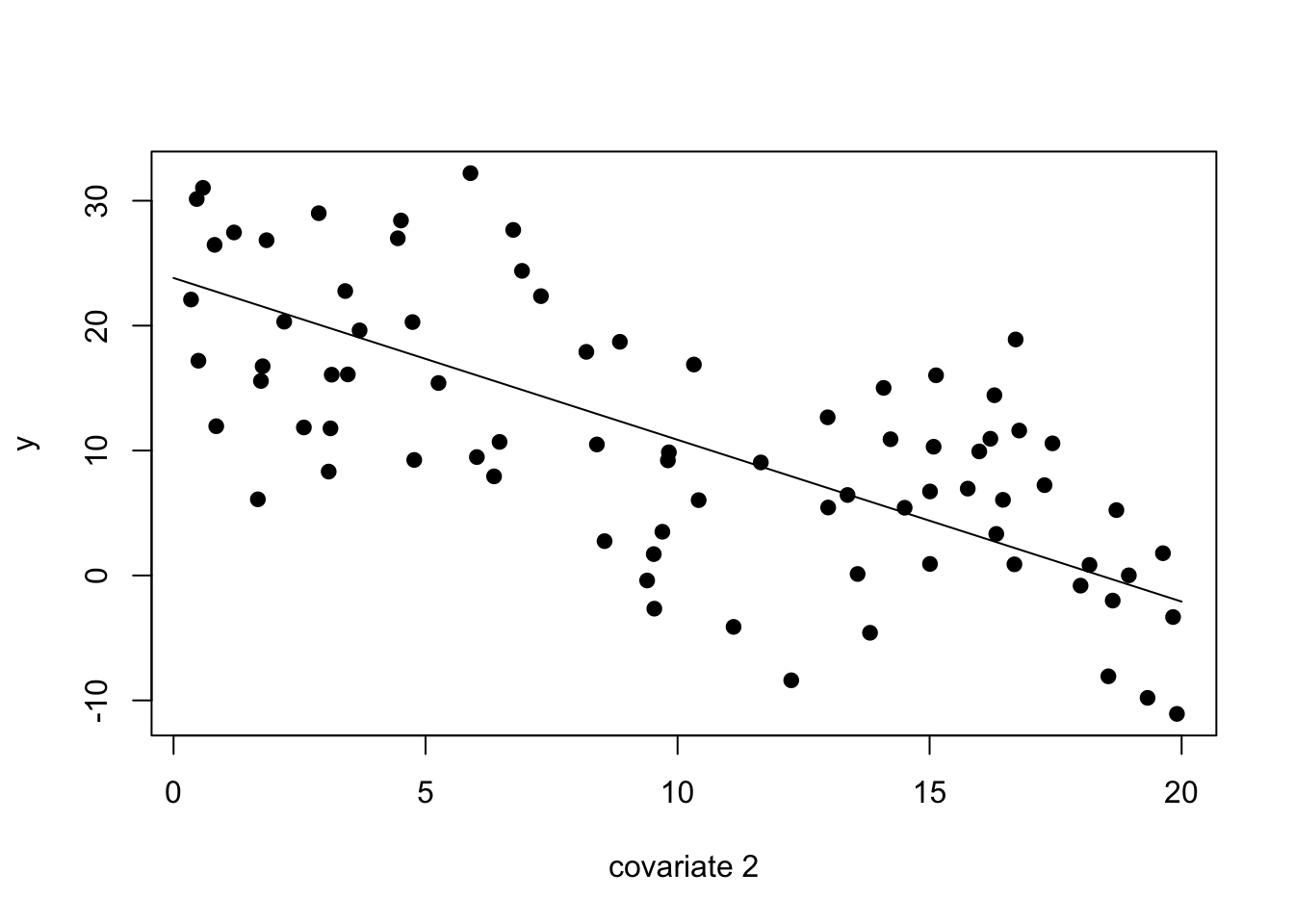
Let’s determine the expected values of \(y\) for input variable 2 (\(x_2\)) and plot it.
# Prediction for covariate 2 when all other input vars at meanmy_df=data.frame(xmat[,2:5])head(my_df)
# Re-run the model but with just the input variables, # and the intercept is implicitm2=lm(y~1+X1+X2+X3+X4, data =my_df)# Now let's try to predict y across a range of # input variable 2,# while holding the other input variables at# their average valuesn_pred=100new_df=data.frame( X1 =rep(mean(my_df$X1), n_pred), X2 =seq(0, 20, length.out =n_pred), X3 =rep(mean(my_df$X3), n_pred), X4 =rep(mean(my_df$X4), n_pred))y_pred2=predict(m2, newdata =new_df)# Now plot:par(mfrow=c(1,1))plot(y~my_df$X2, pch =19, xlab ="covariate 2", ylab ="y")lines(y_pred2~new_df$X2)
Now we see that the predict() function shows a more intuitive relationship between input variable \(x_2\) and outcome \(y\), while accounting for the effects of the three other input variables.
4.12 Footnotes
4.12.1 Euclidean norm & cross product
We often see the syntax, \(|| a ||\), which is the Euclidean norm of the \(n\)-sized vector \(a\): \[|| a || = \left( \sum_{i=1}^{n} a_i^2 \right) ^ {1/2} ,\] so that when we see \(|| a ||^2\), this results in the sum of squares of vector \(a\), \(\sum_{i=1}^{n} a_i^2\).
In the context of least squares regression, we are trying to minimize the residual sum of squares, where the residuals, \(\epsilon_i\), are in vector, \(\epsilon\). The sum of squares of vector \(\epsilon\) is therefore \(|| \epsilon ||^2\). Algebraically, we can find this value as the cross product of \(\epsilon\), which is \(\epsilon^{T}\epsilon\). Let’s do a coded example with vector \(x\).
# Vector of real numbersx=c(1, 2, 3, 4)# sum of squaressum(x^2)
# Euclidean norm also known as the 2-norm# so sum of squares is 2-norm, squarednorm(x, type ="2")^2
[1] 30
4.12.2solve() and Inverse of matrix
Suppose we have matrices \(A\), \(X\), and \(B\), and the following expression is true: \[AX=B.\]
Then, suppose \(X\) is unknown, such that we want to find the solution for \(X\), when we rearrange: \[X = A^{-1} B,\] where \(A^{-1}\) is the multiplicative inverse of matrix \(A\). To figure this out computationally, we can use the solve() function in R, as long as \(A\) is a square matrix and has an inverse.
# Create A and known XA=matrix(c(1,1,5,2), ncol =2)X=matrix(c(2,3), ncol =1)# Dot product to calculate BB=A%*%X# Suppose you have A and B, but want to find XX_solve=solve(A, B)# Did it work?X; X_solve
[,1]
[1,] 2
[2,] 3
[,1]
[1,] 2
[2,] 3
We can see, then, that solve() is internally evaluating \(A^{-1}\). Remember that \(A^{-1}\) is not trivial to calculate, as it is the matrix that must satisfy: \(AA^{-1} = I\), where \(I\) is an identity matrix. In fact, solve(A) returns the inverse of \(A\), if it exists.
4.12.3 Multiple linear regression with a categorical input
Let’s simulate a case in which we have one categorical input variable that takes on values “low”, “medium”, and “high”, and one continuous input variable.
set.seed(7)n=90sigma=0.8# Xmatrix## Interceptx0=rep(1, times =n)## Categorical input variable### Note that we need to code this as "0" "1" "2" to ### simulate our outcome variable "y"x1=rep(c(0,1,2), each=n/3)x1L=factor(x1, labels =c("low", "med", "high"))## Continuous input variablex2=rnorm(n, 0, 2.5)xmat=cbind(x0,x1,x2)head(xmat)
# Intercept and 2 slopesbetas=c(1.5, 1.2, -1.5)# Simulate outcome variable, as usualy2=xmat%*%betas+rnorm(n,0,sigma)# Plot the relationshipspar(mfrow=c(1,2))plot(y2~x1)plot(y2~x2)
# Run the model## Note that we us the "factor" input variable## "x1L", which has "levels"m_cat=lm(y2~1+x1L+x2)summary(m_cat)
Call:
lm(formula = y2 ~ 1 + x1L + x2)
Residuals:
Min 1Q Median 3Q Max
-1.9182 -0.5032 0.1465 0.5061 1.2139
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.66504 0.13741 12.117 < 2e-16 ***
x1Lmed 1.15971 0.19113 6.068 3.38e-08 ***
x1Lhigh 2.29169 0.19170 11.954 < 2e-16 ***
x2 -1.51229 0.03275 -46.171 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7314 on 86 degrees of freedom
Multiple R-squared: 0.9674, Adjusted R-squared: 0.9663
F-statistic: 851.1 on 3 and 86 DF, p-value: < 2.2e-16
How do we interpret the slopes, because we see there is a separate slope for x1Lmed and x1Lhigh? We can understand better by seeing how the linear model addes up. For instance, what is the expected value of the outcome variable when \(x_1\) is high, and \(x_2 = 2.0\)?
## Using m1_binL:y2_pred=1*coef(m_cat)[1]+# Global average (intercept)0*coef(m_cat)[2]+# Not "med"1*coef(m_cat)[3]+# Yes "high"2.0*coef(m_cat)[4]# x2=2.0 * slopeas.numeric(y2_pred)
[1] 0.9321446
When we assigned the slope of the categorical input variable as \(1.2\), remember this is the expected change in \(y\) as the input variable changes by a value of \(1.0\). In the model, we code the \(x_1\) variable as taking numerical values \(0\), \(1\), and \(2\) to represent categories, “low”, “medium”, and “high”. So, the slope for x1med is the expected change in \(y\) as the input variable changes from “low” to “medium”, an effective change of \(1.0\). Then, the slope for x1high is the expected change in \(y\) as the input variable changes from “low” to “high”, an effective change of \(2.0\); hence, this slope is estimated as \(2.29\), with standard error \(0.19\). Notice how this slope is approximately twice our “known” slope for the input variable, which was \(1.2\).
Source Code
# Ordinary Least Squares {#sec-ols}## In-class CodeRemember that our goal is to estimate the linear relationship between data observations of response variable, $y$, and its measured covariate, $x$, following: $Y = XB + \epsilon$, where $\epsilon \sim N(0, \sigma^2 I).$ Our coefficients to estimate are therefore $\hat{B}$, which is a column vector of the intercept and slope. We also estimate the standard deviation of the residuals (i.e., residual error), $\hat{\sigma}$. To estimate the coefficients, we are attempting to minimize the residual sum of squares, $|| \epsilon || ^ 2$. See [Footnotes @sec-crossprod] for more information regarding this notation.## Generate the dataWe'll start with a very small data set to emphasize the basics, and then the in-class activity will go into more depth. Here, we'll implement the OLS estimation with a single covariate that we demonstrated in lecture.```{r}n =4# number observationsp =2# number of parameters# Covariate:x0 =c(1,1,1,1) # placeholder for interceptx1 =c(2,3,5,1) # value of xxmat =matrix(data =c(x0,x1), nrow = n, ncol = p)xmat# Coefficients:## betas[1]: intercept## betas[2]: slopebetas =c(4, 2)xmat %*% betas# residualsepsilon =c(0, -1, 1, 3)# Data observations:y = xmat %*% betas + epsilon```## Plot the relationship```{r}# Plot in layers## Create a blank plotting canvas, specifying axis limitsplot(x=NA,y=NA, xlab ="x", ylab ="y",ylim =c(0,max(y)), xlim =c(0,max(x1)))## Add data pointspoints(y ~ x1, pch =19, cex =2)## Add known linear relationshipabline(coef = betas, col ="black", lwd =2)# Show the residuals:segments(x0 = x1, x1 = x1,y0 = y, y1 = y - epsilon)# Show the model predictions, \hat{y}:y_hat = xmat %*% betaspoints(y_hat ~ x1, cex =1.25)```## Estimate the coefficients using R's `lm()` function {#sec-lm-output}```{r}# Run the model:lm_out =lm(y ~1+ x1)# Show the summary outputsummary(lm_out)# Extract the estimated coefficientslm_coef =coef(lm_out)lm_coef```## Estimate the coefficients manuallyNow we will use the matrix algebra and derivation of normal equations to estimate the intercept and slope from the observations, $Y$. Remember that we estimate the coefficient vector, $\hat{B}$ from: $$X^TX \hat{B} = X^T Y$$ $$\hat{B} = (X^TX)^{-1} X^T Y$$ These equations include the multiplicative inverse matrix, $(X^TX)^{-1}$. See the [Footnotes @sec-solve] for more information about inverse matrices and the `solve()` function.```{r}# Let's break up the normal equations into intermediates:xtx =t(xmat) %*% xmat## Use solve() to find inverse of xtx## why solve()? See Appendix, linked above.inv_xtx =solve(xtx)xty =t(xmat) %*% ybhat = inv_xtx %*% xty# More efficient:# Remember, xtx * bhat = xty# So we can use solve() againbhat_solve =solve(xtx, xty)# Are they the same?# How does this manual solution compare to lm()'s solution?```## Plot the *estimated* relationships {#sec-est-plot}```{r}# Plot in layers## Create a blank plotting canvas, specifying axis limitsplot(NA,NA,xlab ="x", ylab ="y",ylim =c(0,max(y)),xlim =c(0,max(x1)))## Add data pointspoints(y ~ x1, pch =19, cex =2)## Add known linear relationshipabline(coef = betas,col ="black", lwd =2)# Show the residuals:segments(x0 = x1,x1 = x1,y0 = y,y1 = y - epsilon,)# Show the model predictions, \hat{y}:y_hat = xmat %*% betaspoints(y_hat ~ x1,cex =1.25)# Add the lm() estimate:abline(coef = lm_coef,col ="orange", lty =2, lwd =2)# Add the manual OLS estimate:abline(coef = bhat_solve,col ="purple", lty =3, lwd =2)```## Why are the $\hat{B}$ different from true $B$?Remember, we are estimating the coefficients by minimizing the sum of squared errors (SSE), $|| \epsilon ||^2$.```{r}# True sum of squares:sum(epsilon^2)# Estimated (i.e., minimized sum of squares):## From lm()sum(lm_out$residuals^2)## From manual OLSsum( (y - xmat %*% bhat_solve)^2 )```You can see that the OLS strategy minimized SSE, but this is actually lower than the true SSE.## Understanding Uncertainty in $\hat{B}$While the OLS analysis estimates the regression coefficients, $\hat{B}$, from the observed data $Y$, our estimates of these coefficients have error (i.e., uncertainty), such that the estimates are only as good as the data. Specifically, if we have fewer data points (i.e., $n$ is low), we have less certainty in $\hat{B}$. In lecture, we showed, that:$$\hat{B} \sim N \left( B, (X^TX)^{-1} \hat{\sigma}^2 \right), $$and we know that $\hat{\sigma}^2$ depends on sample size $n$, following:$$\hat{\sigma}^2 \quad = \quad \frac{1}{n-p} (Y_{obs} - Y_{pred})^T (Y_{obs} - Y_{pred}) \quad = \quad \frac{1}{n-p} \hat{\epsilon}^T \hat{\epsilon}$$Using these equations, we showed then that $SE(\beta_i) = \sqrt{diag\left( (X^TX)^{-1} \right)_i \hat{\sigma}^2}$. Let's calculate this manually and compare to the output of the `lm()` function.```{r}# Extract the model summary, which has useful componentslm_out_summary =summary(lm_out)# Extract the estimated residual standard deviation, sigmaest_sigma = lm_out_summary$sigmaest_sigma# We already calculated (X^T X)^{-1} as inv_xtxbeta_cov_mat = inv_xtx * est_sigma^2beta_cov_matse_beta =sqrt(diag(beta_cov_mat))se_beta```Compare these values to the output of the `summary()` of @sec-lm-output in the column labelled `Std. Error`. ## Confidence Intervals for $\hat{B}$ {#sec-conf-beta}To calculate confidence intervals for $\hat{B}$, we first must understand the $t$ (a.k.a. Student's $t$) probability distribution. This distribution represents the case when we are estimating the mean of a normally distributed variable and either the sample size is small or the variable's standard deviation is unknown. Essentially, the $t$ distribution increases the uncertainty (i.e., variance) in cases of low sample size (i.e., small $n$). With low sample size (and/or high number of parameters), the degrees of freedom of the $t$-distribution, $\nu$ is low, whereas with high sample size, $\nu$ is large. As $\nu$ approaches infinity, the $t$-distribution approximates the standard normal distribution (i.e., $N(\mu, \sigma)|\mu=0,\sigma=1$). ```{r}#| echo: false# Generate x sequencen_seq =1000x_seq =seq(-10, 10, length.out = n_seq)t_pdf_nu2 =dt(x_seq, df =2)t_pdf_nu100 =dt(x_seq, df =100)norm_pdf =dnorm(x_seq, mean =0, sd =1)# compare to t-100plot(NA,NA, xlab ="x", ylab ="P(x)", xlim =range(x_seq), ylim =c(0, 0.5))lines(norm_pdf~x_seq, col ="red", lwd =3)lines(t_pdf_nu2~x_seq, col ="blue", lwd =3)lines(t_pdf_nu100~x_seq, col ="blue", lwd =2.5, lty =2)legend(x =2.5, y =0.4,legend =c("Standard Normal", expression(italic(t)[2]), expression(italic(t)[100])),lty =c(1,1,2), lwd=c(2,2,2), col =c("red", "blue", "blue"), bty ="n")```It is the case for $\hat{B} \sim N \left( B, (X^TX)^{-1} \hat{\sigma}^2 \right)$ that we do not know the mean ($B$), and we are estimating the variance, $\hat{\sigma}^2$. Specifically, we are estimating the true mean vector, $B$, as $\hat{B}$, and we are estimating the variance of the residuals as $\hat{\sigma}^2$. We can therefore re-write the uncertainty in $\hat{B}$ as a multivariate $t$ distribution: $$(\hat{B} - B) \sim t_{\nu} \left( 0, \Sigma \right),$$where the means are zero, $\nu$ is the degrees of freedom (i.e., $n-p$), and $\Sigma = (X^TX)^{-1} \hat{\sigma}^2$. $(\hat{B} - B)$ represents the deviation of the estimated coefficients from the true coefficients, which is why the distribution is centered around zero. It is perhaps easier to separate the individual estimated coefficients, $\beta_i$, into their separate $t$-distributions:$$\frac{(\hat{\beta}_i - \beta_i)}{SE(\hat{\beta}_i)} \sim t_{\nu}$$$$(\hat{\beta}_i - \beta_i) \sim t_{\nu} SE(\hat{\beta}_i),$$which shows that the $t$-distribution that describes the deviation of regression coefficients from the true value of those coefficients is scaled by the uncertainty in the estimated coefficients $SE(\hat{\beta}_i)$. As shown in Dr. Barber's materials, using this information, we can derive the confidence interval (at the $\alpha$ confidence level) calculation for $\hat{\beta}_i$ as: $$ \hat{\beta}_i \pm t \left(\frac{1-\alpha}{2}, \nu \right) SE(\hat{\beta}_i),$$where the $t()$ notation represents the *critical value* of the $t$-distribution, $t_{crit}$, with $\nu$ degrees of freedom, for which $P(z \le t_{crit}) = \frac{1-\alpha}{2}$, and $z$ is a continuous, random variable. This critical value can be calculated in R using the `qt()` function, which we show below. ::: {.callout-note}## Covariance of $\hat{\beta}_i$Although it is convenient and easier to digest the confidence interval of individual $\hat{\beta}_i$, we must realize that the estimates of the $\beta_i$ can covary (i.e., have non-zero covariance), which is quantified in the variance-covariance matrix of $\hat{B}$, $(X^TX)^{-1} \hat{\sigma}^2$. We will show why this is important below.:::Let's manually calculate the 95% confidence intervals in $\hat{B}$ and compare to R's internal function `confint()`.```{r}# Extract the degrees of freedom from the model (\nu)# which can also be calculated as n - pt_df = lm_out$df.residual# Calculate t critical for alpha = 0.05# This will give us the 95% conf interval (CI)t_crit =qt(1-(0.05/2), df = t_df)# Calculate the upper and lower CI for both betasci_int = lm_coef[1] +c(-1,1)*t_crit*se_beta[1]ci_slope = lm_coef[2] +c(-1,1)*t_crit*se_beta[2]# Construct a table of valuesci_mat =rbind(c(lm_coef[1], ci_int),c(lm_coef[2], ci_slope))colnames(ci_mat) =c("coef", "lowCI", "highCI")rownames(ci_mat) =c("intercept", "slope")ci_mat# Compare these manual calculations to built-in# function confint(), which by default extracts the # 95% CI for a lm() model's coefficientsconfint(lm_out)```## Propagate uncertainty in $\hat{B}$ for predictions of $Y$There are several ways to calculate and visualize our uncertainty in model predictions of observed data $Y$ and unobserved data of the dependent variable (i.e., interpolation). The colored lines drawn on the figure in @sec-est-plot represent the expected values of $Y$ based on the OLS analysis' estimate of $\hat{B}$, but this line does not include uncertainty in these coefficient values. ### Multivariate $t$-distribution methodFirst, we will calculate uncertainty by sampling from the multivariate $t$ distribution that represents error in regression coefficients, $\hat{B}$. ```{r}# We will "bootstrap" 1000 samples of intercept and slopeset.seed(3)n_samp =500# Draw from the multivariate t # which represents (\hat{B} - B)test_mat_deviates = mnormt::rmt(n_samp, mean =c(0,0), S = beta_cov_mat, df = t_df)# Now calculate the realized intercept and slope# using the t-distributed deviatestest_mat_t =cbind( lm_coef[1] +c(test_mat_deviates[,1]), lm_coef[2] +c(test_mat_deviates[,2]))# Calculate the 95% quantiles and compare to the # calculated 95% confidence intervals from aboveapply(test_mat_t, MARGIN =2, # applies function (FUN) to columns (dim 2)FUN = quantile, probs =c(0.025, 0.5, 0.975))# Compareci_mat# Plot the relationship between intercept and slope# Notice the covarianceplot(test_mat_t, xlab ="Intercept", ylab ="Slope")```Next, for each pair of intercept and slope randomly drawn above, we will calculate the expected values of $Y$ across the range of covariate $x$. We will then summarize the 95% quantile of expected $Y$ at each value of $x$ in this interpolation. To do this, we need a function to calculate the expected value of $Y$. This function will have the intercept and slope as inputs and will output the expected values of $Y$ across a range of $x$. Then, we will `apply()` this function using all of the values of intercept and slope, in a vectorized and therefore very efficient manner, rather than using any `for` loops. ```{r}# Create a matrix that holds the values of x# over which we want to interpolate the expected# values of Yx_fake_mat =cbind(rep(1, times =100),seq(0,max(x1),length.out =100) )# Create a function that will calculate the expected valuesy_hat_fun =function(x, x_mat){ x_mat %*% x}# Apply this function to all intercepts and slopes that# we drew from the multivariate ty_pred_mt =apply(test_mat_t, 1, y_hat_fun, x_mat=x_fake_mat)# Summarize the 95% quantile of the expected value of Y# at each value of x y_pred_mt_summary =apply(y_pred_mt, 1, quantile, probs =c(0.025, 0.975))str(y_pred_mt_summary)```### `predict()` function methodR has a built-in function `predict()` (see specific variant `predict.lm()`) which calculates expected values of the dependent variable from a linear regression model estimated using the function `lm()`.```{r}# Note that 'newdata' must be a data frame that includes the ranges# of each covariate in the regression model for which you want # to generate interpolated or predicted values of the dependent variable# Here we are calculated the expected values as well as the # 95% confidence intervals for those expected valuesy_predict =predict(lm_out,newdata =data.frame(x1 =c(x_fake_mat[,2])),interval ="confidence", level =0.95)str(y_predict)```### Compare the two methods Let's visualize the output of the two methods to compare. ```{r}# plotplot(x=NA,y=NA,xlab ="x", ylab ="y",xlim =c(0,max(x1)), ylim =c(-5, 25), pch =19)# Plot the expected values of Y for each pair of int/slope for(i in1:n_samp){lines(y_pred_mt[,i] ~ x_fake_mat[,2],# Reduce the opacity of each linecol = scales::alpha("black", alpha =0.1), lwd =2)}# Add the data pointspoints(y ~ x1, col ='orange', pch =19, cex =2)# Add the expected values of Y from \hat{B}abline(coef = lm_coef, col ="orange", lwd =3)# Add the conf int of expected Y using multivariate tlines(y_pred_mt_summary[1,] ~ x_fake_mat[,2], lty =2, lwd =3, col ="orange")lines(y_pred_mt_summary[2,] ~ x_fake_mat[,2], lty =2, lwd =3, col ="orange")# Add the conf int of expected Y using predict() functionlines(y_predict[,"lwr"]~ x_fake_mat[,2], lty =3, lwd =3, col ="purple")lines(y_predict[,"upr"]~ x_fake_mat[,2], lty =3, lwd =3, col ="purple")```There is yet a third option to calculate the uncertainty in predicted (i.e., interpolated or extrapolated) values of $Y$, which is to derive an exact calculation of the confidence interval using the $t$ distribution, similar to that shown in @sec-conf-beta. See Ch4.1 of Dr. Barber's book for this derivation. ## Multiple Linear RegressionSo far, we have only discussed a single input variable in our model, which is a simple linear regression. When we have multiple input variables, we are dealing with multiple linear regression analysis, so the model looks like:$$y_i = \beta_0 + \beta_1 x_{1,i} + \beta_2 x_{2,i} + \dots + \beta_{p-1} x_{p-1,i} + \epsilon_i$$where $p$ is the number of model coefficients and $p-1$ is the number of input variables. Still, in matrix notation the model is $Y = XB + \epsilon$, so the least squares regression analysis approach still works. However, our interpretation of the model coefficients becomes a bit more challenging. Let's look at a data set within the `faraway` package.```{r}#| message: false#| warning: false#| fig-width: 8#| fig-height: 3.5library(faraway)data(gala)# Plot the raw data relationshipspar(mfrow=c(1,3))plot(gala$Species ~ gala$Elevation, xlab ="Elevation", ylab ="Species", pch =19)plot(gala$Species ~ gala$Area, xlab ="Area", ylab ="Species", pch =19)plot(gala$Species ~ gala$Adjacent, xlab ="Adjacent", ylab ="Species", pch =19)par(mfrow=c(1,1))# Conduct multiple and single linear regressionm, focusing on Elevationm1 =lm(Species ~ Elevation + Area + Adjacent, data = gala)m2 =lm(Species ~ Elevation, data = gala)coef(m1); coef(m2)``````{r}plot(gala$Species ~ gala$Elevation, xlab ="Elevation", ylab ="Species", pch =19)abline(coef=coef(m1)[1:2])abline(coef=coef(m2)[1:2], lty =2)```What we see above is how the addition of `Area` and `Adjacent` input variables into the model "adjusts" the effect of `Elevation`, leading to two unique estimates of the slope (i.e., effect) of `Elevation`. Let's probe multiple linear regression more closely by using simulated data.First, let's simulate a model with 80 data points that correspond to observations of 4 input variables and one outcome variable. Note that in [Footnotes @sec-mlr], we show a case with a categorical/binary input variable. ```{r}n =80n_covariate =4p = n_covariate +1betas =vector("numeric", length = p)xmat =matrix(0, nrow = n, ncol = p)sigma =2.25# Column for interceptxmat[,1] =1# Generate the covariate data randomly:set.seed(5)xmat[,2] =rnorm(n, mean =5, sd =8)xmat[,3] =runif(n, min =0, max =20)xmat[,4] =rchisq(n, df =50)xmat[,5] =rpois(n, lambda =10)par(mfrow=c(2,2))for(i in2:p){hist(xmat[,i], main =paste("covariate ", i-1))}# Set the betas:betas[1] =1.0betas[2] =0.75betas[3] =-1.2betas[4] =0.0betas[5] =1.8# Calculate the observed 'y', adding residual errory = xmat %*% betas +rnorm(n, mean =0, sd = sigma)par(mfrow=c(1,1))hist(y)par(mfrow=c(2,2))for(i in2:p){plot(y ~ xmat[,i],xlab =paste("covariate ", i-1))}```How do we figure out the expected value of $y$ for a particular situation? Here's an example. What is the expected value of $y$ when $x_2 = 0.5$, but the rest of the input variables are at their average values?```{r}# Written out long-ways:pred_y = betas[1]*1+ betas[2]*mean(xmat[,2]) + betas[3]*0.5+ betas[4]*mean(xmat[,4]) + betas[5]*mean(xmat[,5]) pred_y```Now let's use ordinary least squares regression to estimate our model coefficients from the data, and then compare these to our "known" values of the model parameters. ```{r}# Run the model:m1 =lm(y ~0+ xmat)# Note that the following two models give the same results#m2 = lm(y ~ 0 + X1 + X2 + X3 + X4 + X5, data = data.frame(xmat))#m3 = lm(y ~ 1 + X2 + X3 + X4 + X5, data = data.frame(xmat))summary(m1)#summary(m2)#summary(m3)# Compare known `betas` to estimated coefficientscbind(betas, coef(m1)) # plot the regression lines with ablinecoef_m1 =coef(m1)par(mfrow=c(2,2))for(i in2:p){plot(y ~ xmat[,i], pch=19,xlab =paste("covariate ", i-1),ylab ="y",ylim =range(y))abline(coef=coef_m1[c(1,i)])}```Well, those regression lines do not look correct. That is because we are interpretting the slopes and intercepts a little incorrectly and not plotting them in the correct manner. ::: {.callout-note}## How to plot the output of `lm()` for multiple linear regressionWhen we isolate and visualize the relationship between the outcome and a single input variable, what we are really observing is the adjusted relationship, after accounting for the other input variables in the model. To understand the expected value of $y$ for any particular value of the single input variable, we really need to set the other input variables to their mean value. Let's demonstrate this below with the `predict()` function.:::Let's determine the expected values of $y$ for input variable 2 ($x_2$) and plot it.```{r}# Prediction for covariate 2 when all other input vars at meanmy_df =data.frame(xmat[,2:5])head(my_df)# Re-run the model but with just the input variables, # and the intercept is implicitm2 =lm(y ~1+ X1 + X2 + X3 + X4, data = my_df)# Now let's try to predict y across a range of # input variable 2,# while holding the other input variables at# their average valuesn_pred =100new_df =data.frame(X1 =rep(mean(my_df$X1), n_pred),X2 =seq(0, 20, length.out = n_pred),X3 =rep(mean(my_df$X3), n_pred),X4 =rep(mean(my_df$X4), n_pred))y_pred2 =predict(m2, newdata = new_df)# Now plot:par(mfrow=c(1,1))plot(y ~ my_df$X2, pch =19,xlab ="covariate 2", ylab ="y")lines(y_pred2 ~ new_df$X2)```Now we see that the `predict()` function shows a more intuitive relationship between input variable $x_2$ and outcome $y$, *while accounting for the effects of the three other input variables*.## Footnotes### Euclidean norm & cross product {#sec-crossprod}We often see the syntax, $|| a ||$, which is the Euclidean norm of the $n$-sized vector $a$: $$|| a || = \left( \sum_{i=1}^{n} a_i^2 \right) ^ {1/2} ,$$ so that when we see $|| a ||^2$, this results in the sum of squares of vector $a$, $\sum_{i=1}^{n} a_i^2$.In the context of least squares regression, we are trying to minimize the residual sum of squares, where the residuals, $\epsilon_i$, are in vector, $\epsilon$. The sum of squares of vector $\epsilon$ is therefore $|| \epsilon ||^2$. Algebraically, we can find this value as the cross product of $\epsilon$, which is $\epsilon^{T}\epsilon$. Let's do a coded example with vector $x$.```{r}# Vector of real numbersx =c(1, 2, 3, 4)# sum of squaressum(x^2)# Evaluated as cross-productt(x) %*% x## Or with crossprod()crossprod(x,x)# Euclidean norm also known as the 2-norm# so sum of squares is 2-norm, squarednorm(x, type ="2") ^2```### `solve()` and Inverse of matrix {#sec-solve}Suppose we have matrices $A$, $X$, and $B$, and the following expression is true: $$AX=B.$$Then, suppose $X$ is unknown, such that we want to find the solution for $X$, when we rearrange: $$X = A^{-1} B,$$ where $A^{-1}$ is the multiplicative inverse of matrix $A$. To figure this out computationally, we can use the `solve()` function in R, as long as $A$ is a square matrix and has an inverse.```{r}# Create A and known XA =matrix(c(1,1,5,2), ncol =2)X =matrix(c(2,3), ncol =1)# Dot product to calculate BB = A %*% X# Suppose you have A and B, but want to find XX_solve =solve(A, B)# Did it work?X; X_solve```We can see, then, that `solve()` is internally evaluating $A^{-1}$. Remember that $A^{-1}$ is not trivial to calculate, as it is the matrix that must satisfy: $AA^{-1} = I$, where $I$ is an identity matrix. In fact, `solve(A)` returns the inverse of $A$, if it exists.```{r}inv_A =solve(A)#Did it work?(inv_A %*% B)X```### Multiple linear regression with a categorical input {#sec-mlr}Let's simulate a case in which we have one categorical input variable that takes on values "low", "medium", and "high", and one continuous input variable. ```{r}set.seed(7)n=90sigma =0.8# Xmatrix## Interceptx0 =rep(1, times = n) ## Categorical input variable### Note that we need to code this as "0" "1" "2" to ### simulate our outcome variable "y"x1 =rep(c(0,1,2), each=n/3)x1L =factor(x1, labels =c("low", "med", "high"))## Continuous input variablex2 =rnorm(n, 0, 2.5)xmat =cbind(x0,x1,x2)head(xmat)# Intercept and 2 slopesbetas=c(1.5, 1.2, -1.5)# Simulate outcome variable, as usualy2 = xmat %*% betas +rnorm(n,0,sigma)# Plot the relationshipspar(mfrow=c(1,2))plot(y2~x1)plot(y2~x2)# Run the model## Note that we us the "factor" input variable## "x1L", which has "levels"m_cat =lm(y2 ~1+ x1L + x2)summary(m_cat)coef(m_cat)```How do we interpret the slopes, because we see there is a separate slope for `x1Lmed` and `x1Lhigh`? We can understand better by seeing how the linear model addes up. For instance, what is the expected value of the outcome variable when $x_1$ is `high`, and $x_2 = 2.0$?```{r}## Using m1_binL:y2_pred =1*coef(m_cat)[1] +# Global average (intercept)0*coef(m_cat)[2] +# Not "med"1*coef(m_cat)[3] +# Yes "high"2.0*coef(m_cat)[4] # x2=2.0 * slopeas.numeric(y2_pred)```When we assigned the slope of the categorical input variable as $1.2$, remember this is the expected change in $y$ as the input variable changes by a value of $1.0$. In the model, we code the $x_1$ variable as taking numerical values $0$, $1$, and $2$ to represent categories, "low", "medium", and "high". So, the slope for `x1med` is the expected change in $y$ as the input variable changes from "low" to "medium", an effective change of $1.0$. Then, the slope for `x1high` is the expected change in $y$ as the input variable changes from "low" to "high", an effective change of $2.0$; hence, this slope is estimated as $2.29$, with standard error $0.19$. Notice how this slope is approximately twice our "known" slope for the input variable, which was $1.2$.